DeepSeek-R1 has created quite a stir in the AI world, with headlines all over the place, primarily focusing on the low cost aspects of it to create a competitive model that butts head with o1 reasoning models from OpenAI.
I was more curious on the Reinforcement Learning aspects of it which I feel is step change for how these models are built. Some private labs may have already discovered this but its good to have these techniques now in the open and also proving their usefulness.
Current challenges
For Supervised Fine Tuning, you need a decent amount good quality data which either needs to be annotated by humans or through synthetic data generation where you would then need to filter between good vs bad generated data. This is a cumbersome process and also costly. For training reasoning, you would need data that would contain the reasoning step and there is not a whole lot of data on internet that does that.
One of the earlier emergent LLMs behavior was the Chain of Thought, which essentially was that when you ask LLM to "think step by step", you would get reasoning steps and generally a better answer. DeepSeek-R1 uses this technique to train a model to make reasoning part of its response, out of the box.
Reinforcement learning
The mechanism they used was Reinforcement Learning (RL), which refers to training the model through trial-and-error by rewarding outputs that contain correct, verifiable answers and reasoning steps. This iterative process helped the LLM systematically improve its reasoning capabilities as it learned from the reward signals.
There have been other approaches to train LLMs using reinforcement learning, but till now many of them were costly; either requiring more data, or more complex training, leading to costly training. What DeepSeek has done is make it cheaper and scalable to use RL for LLM training and avoiding Supervised Fine Tuning (SFT).
The main part of the training that help achieve this was Group Relative Policy Optimization. Its a reinforcement learning method which avoids a separate critic model (in previous research) by sampling multiple answers for a question and using group scores to estimate the baseline, which lowers the resources needed for training.
DeepSeek-R1-Zero
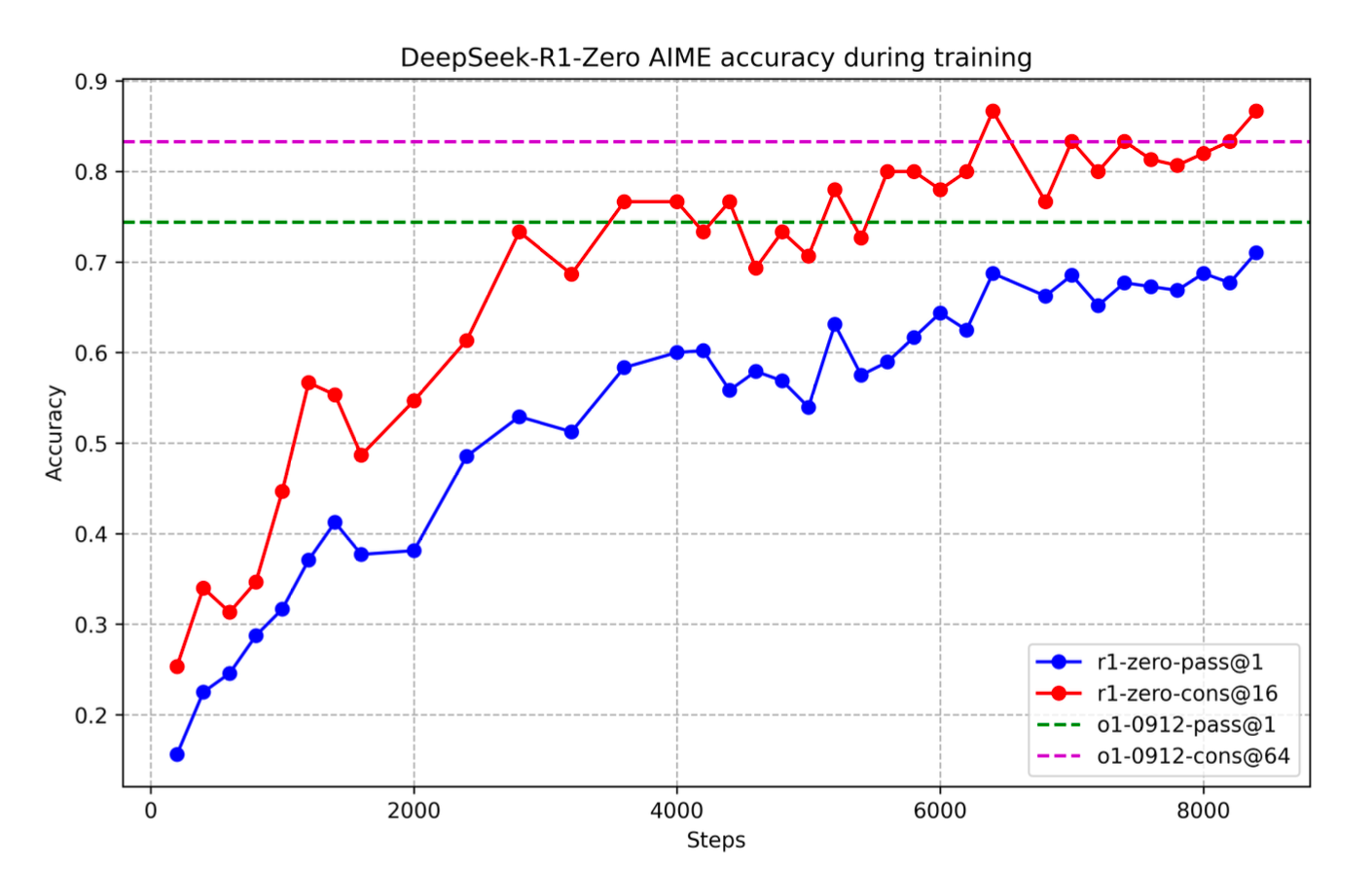
This is where they used DeepSeek-V3-Base as the base model and applied reinforcement learning to enhance reasoning capabilities. While successful, they noticed the model's outputs had readability issues and occasionally mixed different languages.
Training Process
The reinforcement learning approach relied on multiple reward functions. Reward functions take the output and then give some +ve, 0, -ve reward.
- Rule-based Rewards: They used questions with verifiable answers (code, math, logic) from their dataset. The model had to generate both reasoning steps and the final answer. Accurate answers received rewards while incorrect don't.
- Format Rewards: The model received additional rewards for following specific output formats, using
<think>...</answer>tags followed by<answer>...</answer>tags.
During each reinforcement cycle, the model:
- Generated multiple outputs for each question
- Received rewards based on correctness and format
- Used Group Reward Policy Optimization (GRPO) to incrementally improve towards better-rewarded outputs
Emergent Behaviors
What's fascinating is that they only provided a simple system prompt asking for reasoning in a specific format, without dictating how to reason. During training, the model developed self-reflection, self-verification capabilities, often re-evaluating and adjusting its reasoning mid-process. It also learned to reason for longer as the training went on.
This demonstrates the power of reinforcement learning - you don't explicitly teach how to reason, but rather let the model learn through rewards. This approach could potentially be applied to train models for various other capabilities, as long as you can create verifiable rewards. While this opens new possibilities for model development with less data dependency, some initial bootstrap data remains important (as we'll discuss later).
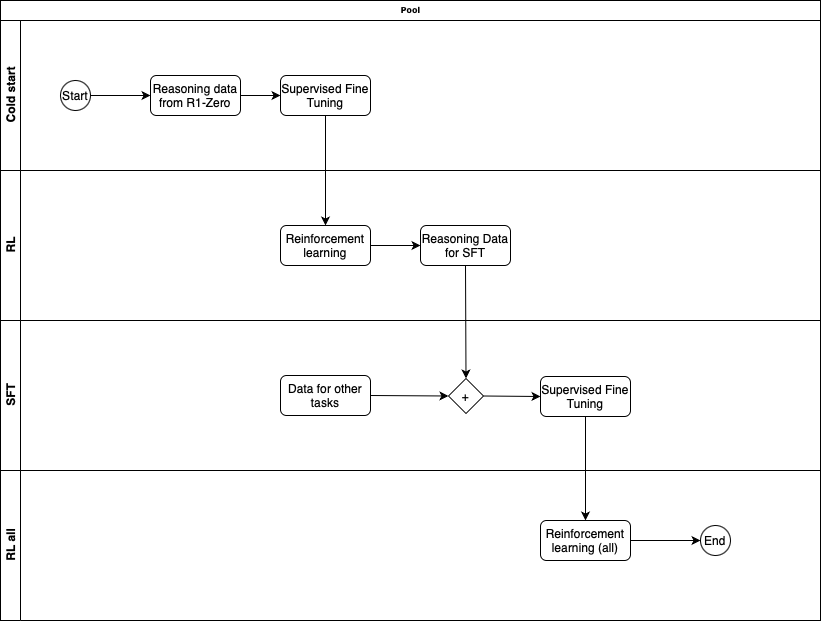
DeepSeek R1
Because of some of the issues with R1 e.g. readability, mixing of language, likely degradation on tasks that weren't specifically had verifiable rewards e.g. creative writing etc. they trained R1 to improve the overall usability of the model.
R1 was trained in multiple phases
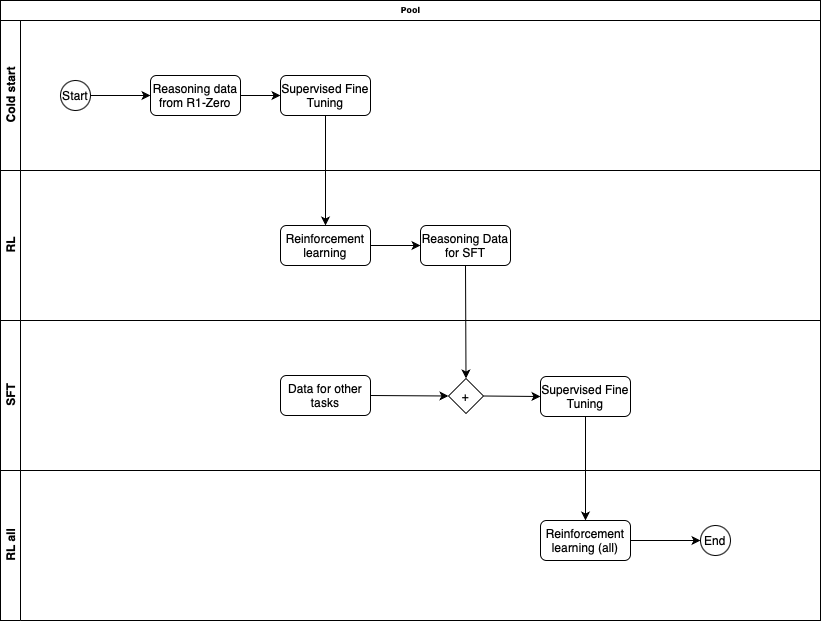
Phase 1 - Cold start with SFT
Taking DeepSeek-V3-Base, used Supervised Fine Tuning on cold-start data that was collected from R1-Zero checkpoint. The data was likely handpicked to make sure it is of high quality.
Phase 2 - Reasoning oriented RL
Similar to R1-Zero, this phase used RL to train on reasoning related tasks on verifiable questions/answers. They did add another reward in the process which was Language Consistency Reward. This reward made sure the model avoided language mixing. Later they ran ablation experiments, where they remove this reward to understand its impact. What they saw was that Language Consistency Reward did decrease model performance but as it led to more human readable model, so its worth having.
Phase 3 - Rejection sampling and SFT
After the Phase 2 is completed, from that model checkpoint, they collect more data for Supervised Fine Tuning for subsequent round. But here they not only have reasoning oriented data but also data for other domains e.g. creative writing, role-playing, general tasks to make sure the model is well rounded. Gathering good data is important.
For reasoning related data, they generate data containing accurate answers, doesn't have mixed-languages or long paragraph etc. At the end of process they have 600K reasoning related training samples.
For non-reasoning data, they use data they had for SFT in the DeepSeek-V3 model. The use DeepSeek-V3 to also generate reasoning data for such tasks, but also exclude it for tasks that don't require reasoning so that model also learns to avoid reasoning when its not needed.
Using all this data they train the DeepSeek-V3-Base with this curated dataset of 800K samples.
Phase 4 - RL for all scenarios
In this final state a round of Reinforcement Learning is done, but not only on reasoning data but also on other data where the reward is based on human preference. There is also safety related (harmlessness) evaluation done during this phase.
At the end of all these phases we get the DeepSeek-R1 model and my vibe check on that model has been pretty good.
Distillation
Lastly they use the R1 model to generate 800K sample data and use Supervised Fine Turning on various small language models e.g. Llama-3.3-70b-Instruct, Qwen2.5-32b etc. and observe that those models overall improve in complex tasks requiring reasoning.
The other interesting thing they also observe is that directly using RL on those models similar to R1-Zero, doesn't improve those models as much as distillation from larger model does.
Whats likely to happen next
The year 2025 is going to be interesting, we are going to see much more research in direction of RL, many more distilled small models with reasoning capabilities that will be SOTA. The test time scaling will be something that Open source/weights models will also be pushing in direction off. Likely more (verifiable) domain specific small models may become easier to train due to RL. Anything that you can verify relatively cheaply in training process, you are likely to see much improvements in models related to those.
We are already seeing various OpenSource capability to train using RL (e.g. Unsloth). Here is my attempt to train reasoning with emojis in each step using Unsloth 😄
<reasoning>
Her 200 sheep each produced 10 pounds of wool, so the total amount of wool is 200 * 10 = 2000 pounds 🐑.
She sold one pound of wool for $20, so the total revenue is 2000 * $20 =$40,000 💸.
The cost to her was $2000 💸.
So, her profit is $40,000 - $2000 = $38,000 🤑.
</reasoning>
<answer>
$38000
</answer>
Its certainly going to be exciting 2025 for open source models.
Disclaimer: I'm no ML/AI expert, but a curious engineer who has been learning more about the inner workings of the LLMs to try to understand better the new techniques (when it comes to using them) and also how these models are becoming better. If you find something incorrect in my understanding please leave a comment.