Ollama is a powerful and user friendly tool for running and managing large language models (LLMs) locally. But not all latest models maybe available on Ollama registry to pull and use. The fastest way maybe to directly download the GGUF model from Hugging Face. In this article, we'll explore how to install a custom Hugging Face GGUF model using Ollama, enabling you to try out latest models as soon as they are available.
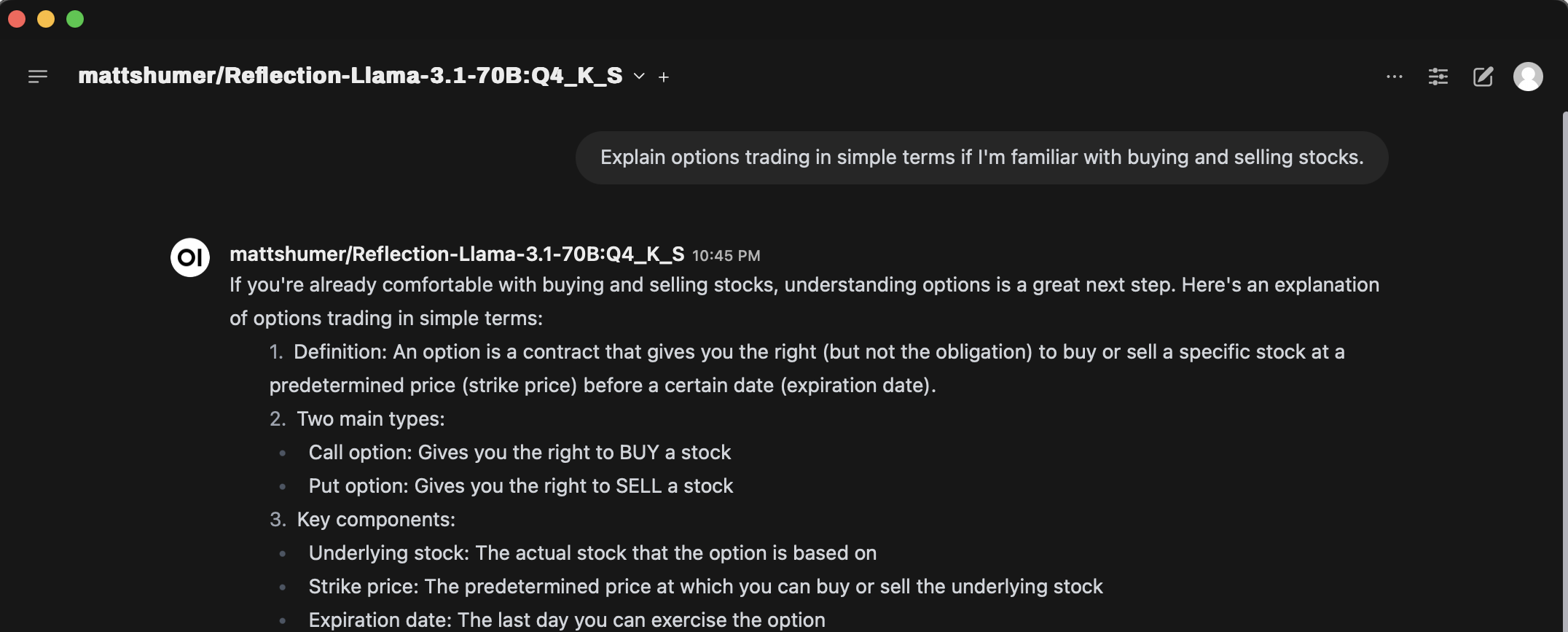
I use Open-WebUI as the interface for Ollama, and all these instructions would allow you to use the model from Open-WebUI as well.
1. Download the Model
First, we need to acquire the GGUF model from Hugging Face. We'll use the Hugging Face CLI for this:
huggingface-cli download --help bartowski/Reflection-Llama-3.1-70B-GGUF Reflection-Llama-3.1-70B-Q4_K_S.gguf
This command downloads the specified GGUF model, which in this case is a fine-tuned version of LLaMa 3.1.
2. Create a Modelfile
Modelfile is the blueprint that Ollama uses to create and run models. Since we're working with a LLaMa 3.1 variant, we can base our Modelfile on an existing one:
ollama show --modelfile llama3.1:70b-instruct-q4_0 >> Modelfile
This command generates a Modelfile based on the llama3.1 model specifications which I already had locally pulled.
If you don't have example of existing Modelfile to reuse then you would need to figure it out from the Hugging-Face page for the model and then create one.
3. Update the Modelfile
Now, we need to modify the Modelfile to point to our downloaded GGUF model. Open the Modelfile in a text editor and update the FROM line with the path to the downloaded model. The Hugging Face CLI will have printed this path at the end of the download process.
4. Create the Model in Ollama
Finally, we'll use Ollama to create our custom model:
ollama create mattshumer/Reflection-Llama-3.1-70B:Q4_K_S -f Modelfile
This command processes the Modelfile and copies the model to Ollama's storage, typically located at /usr/share/ollama/.ollama. Here mattshumer/Reflection-Llama-3.1-70B:Q4_K_S is the name of the model that I will use in Ollama, you can name it whatever you want.
If you want to delete the hugging face cached model so you don't use double the storage then you can run the following which will start a Terminal UI for you to select which models to delete.
huggingface-cli delete-cacheBy following these steps, you've successfully installed a custom Hugging Face GGUF model using Ollama and in Open-WebUI.