DeepSeek-R1: A Peek Under the Hood
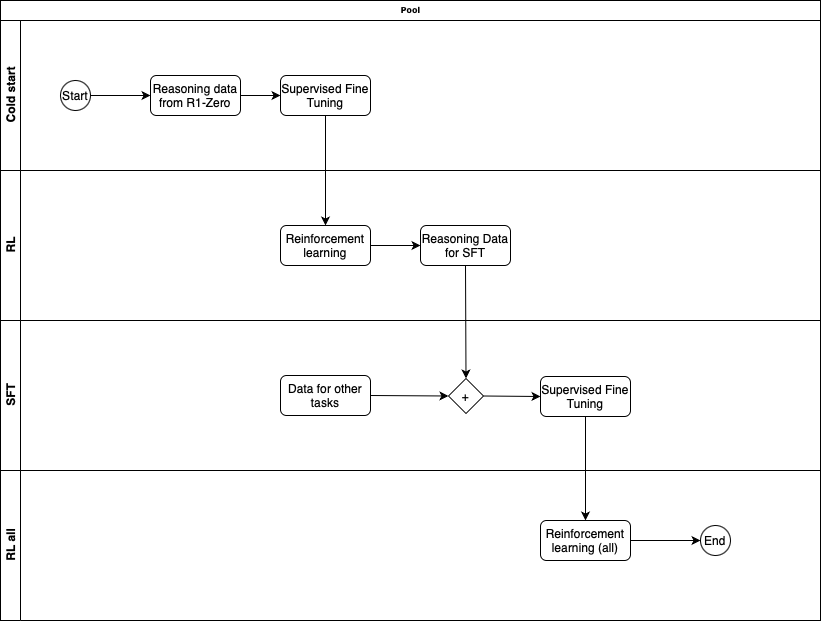
DeepSeek-R1 uses cost-effective Reinforcement Learning to unlock emergent reasoning. By rewarding correct, verifiable steps, it refines logic and answers—showcasing how systematic feedback can reduce data needs and boost performance. Here I discuss my understanding from research paper.