Using LLMs and Cursor to become a finisher
I transitioned to the role of Engineering Manager approximately 5 years ago, since then I haven't been programming in my day job but the itch to do so has always been there. So I continue to work on side projects to not lose touch and continue to hone my skills.
Because my time has always been limited, progress on side projects had been slow in the past, and many remained unfinished as life's events caused a loss of momentum, making them harder to resume. However, in the last year (2024), I have been very productive with my side projects, quickly building the tools or projects I need and deploying them for others to use—in other words, finishing the v1 of each project.
A few examples of what I've built are
- jsonplayground.com - JSON formatter but also in browser JQ using WASM so no data leaves the machine.
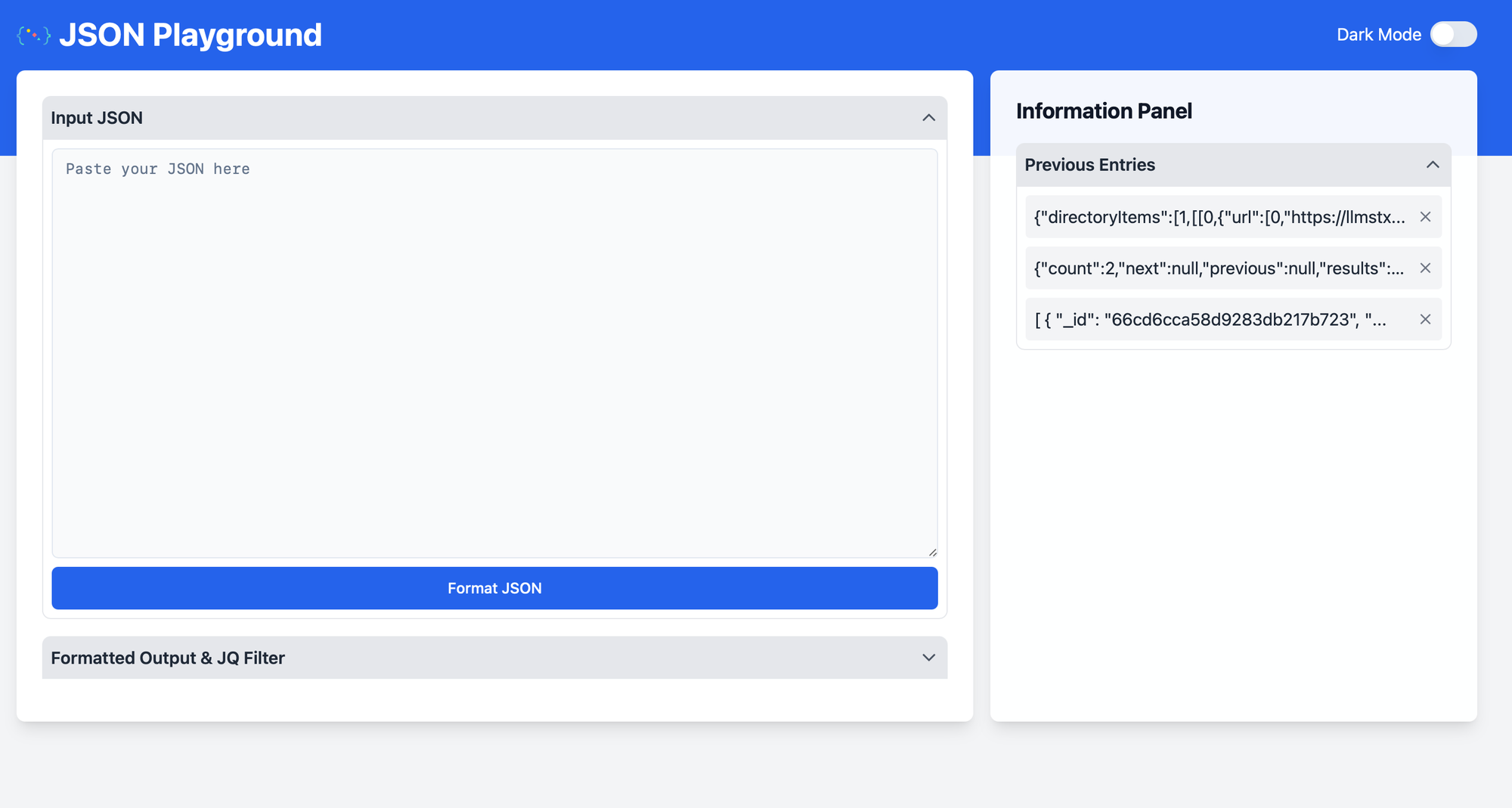
- webtomarkdown.com - As I often feel the need of converting files to Markdown, or parts of website to Markdown for passing in as context to LLMs. I'm currently building this tool to solve that problem.
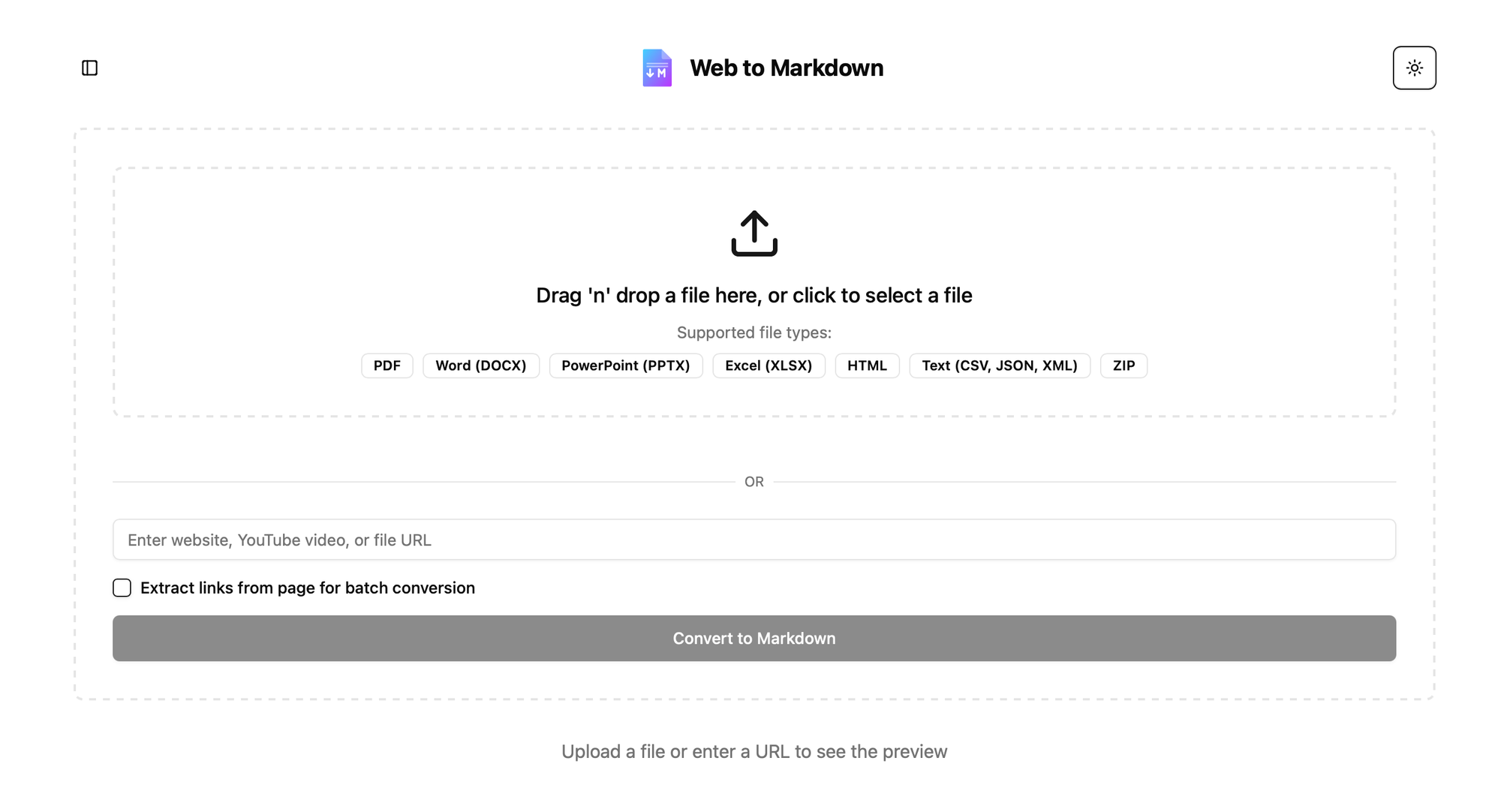
- Face lift for my soaring club page Evergreen Soaring where I volunteer (not deployed yet on official website).
- A Chrome Browser Extension to automate parts of public messages we receive at my soaring club.
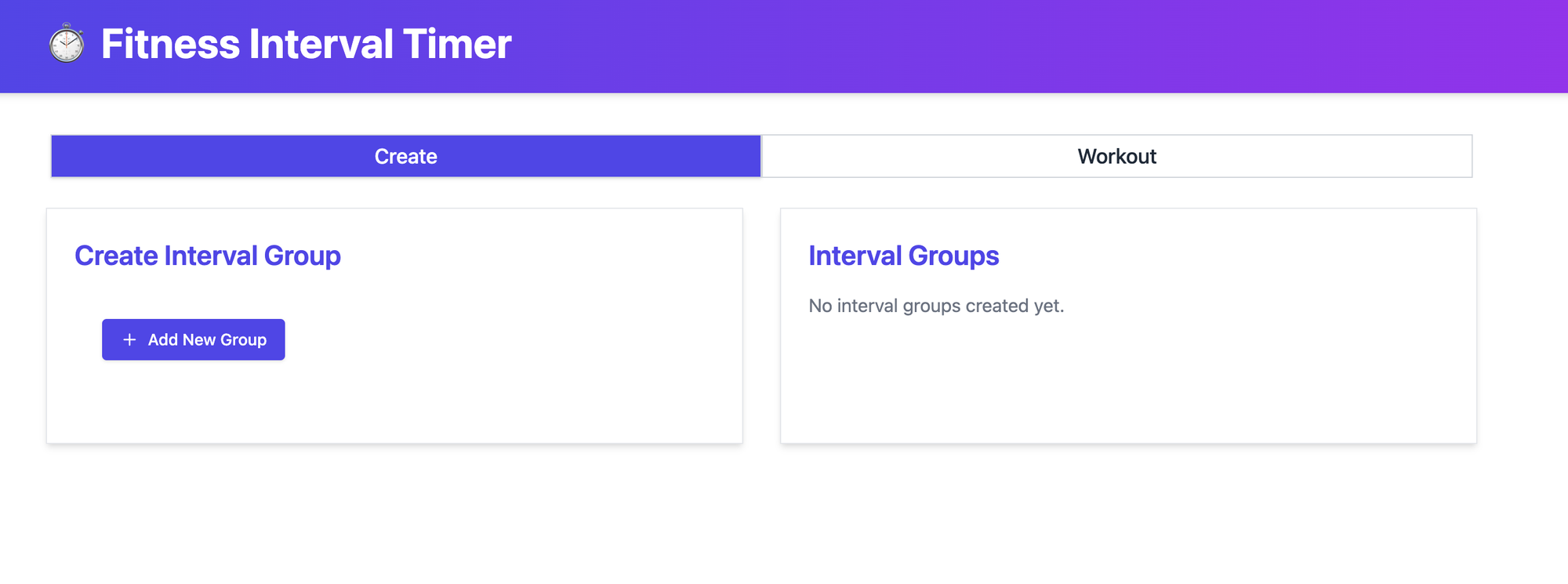
- fitinterval.com - Interval timer for workouts
LLMs in general have been immense booster for my productivity when it comes to side projects and more specifically the Cursor IDE has been a great editor to use these LLMs for coding.
In this blog I'll go over what my high level flow looks like for greenfield projects and I hope that may help you. I do want to acknowledge that these tools are good in certain cases but may annoy you (waste time) in other areas, you just need to use them to figure out where specifically it's useful for you.
I have a nice habit tracker that I would like to replicate as a website, but all data stored locally, so let's use that as an example of what to create here.

Start with a spec
I use the o1 ChatGPT to first get my application specification more refined. The reason I do that is so that it helps me scope the problem and also the spec I get at the end, I use it in further stages of bootstrapping the code. You can try to write the spec yourself, but I feel that going from few sentences to more detailed spec through ChatGPT o1 has been very useful in saving me time. I also ask it to further probe me with questions to further refine it.
Following the prompt I start with.
I’m want to build a website for habit tracking where user sees columns of months and each row being a date. They can simply select to indicate a day where they continued with the habit. It should store all that on local machine. Ask me more questions to refine the idea.
It asks me bunch of questions which I answer, but then it continues asking me more questions. At some point, where you feel there is enough details, you should explicitly ask it to create a spec with the details that will allow another person/AI to build application. I also specify the technology I would prefer to use as thats what I'm familiar with most.
Answer those questions for me reasonably and create a spec that I can give to a person or another AI to help create the website. Make sure to have the details of project, user experience, technical details. I want to use typescript, react, tailwind css.
You can read the whole chat here: Habit Tracking Website Plan
Now store that spec in SPEC.md in a folder where your project will be. We will continue to refer back to it when needed.
Bootstrap project
I use Vite to bootstrap my project. This allows me to setup all the necessary tooling in a consistent manner.
In the directory of project I run npm create vite@latest . which will ask me question about which UX framework and Language to use. Once I have the project and SPEC.md in that project I use the Cursor Agent to create the initial code.
You can go to Composer > Select Agent > Added SPEC.md in the context and ask it to implement it.
This will go over your code, setup tailwind, update few files to create the initial version.
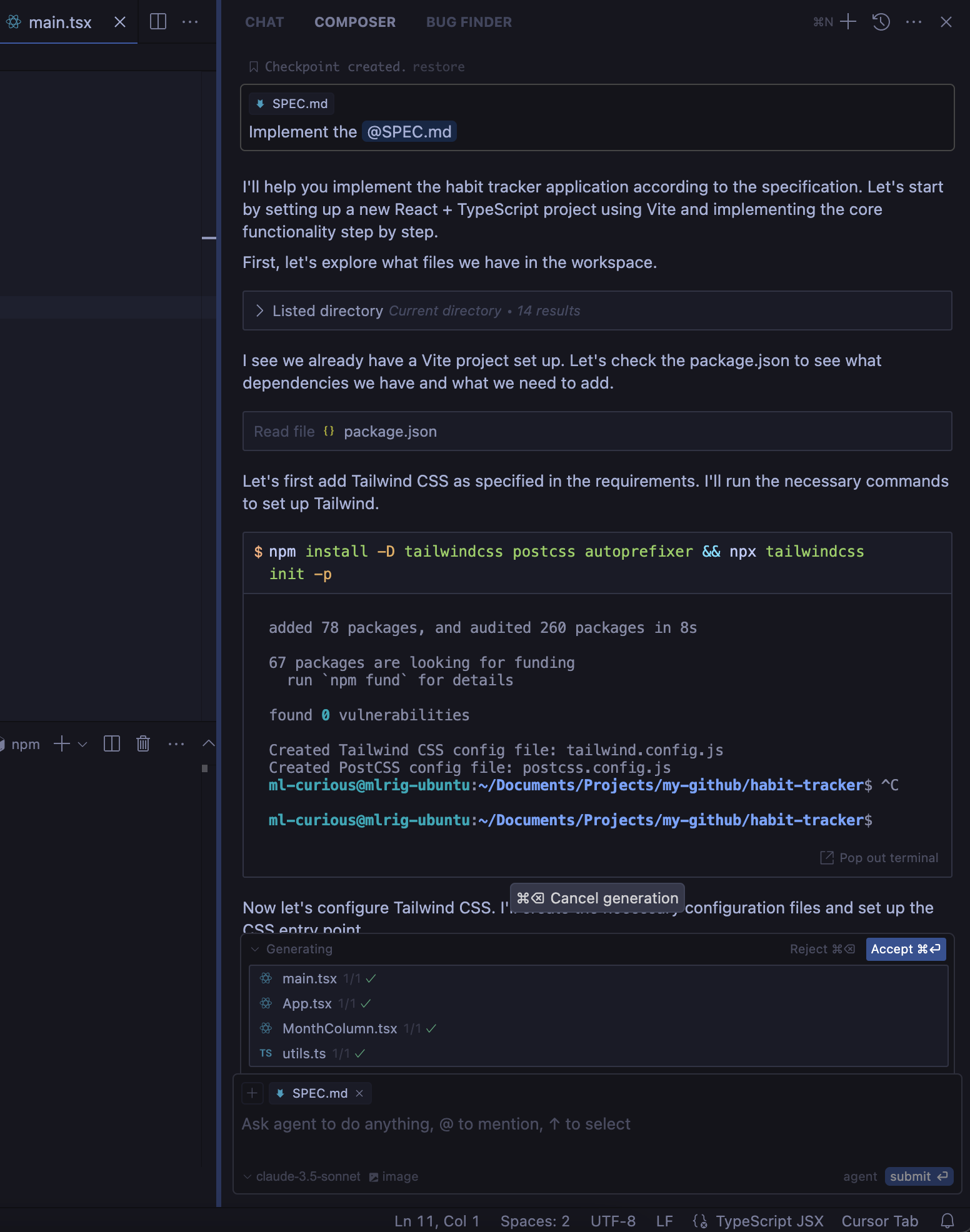
This is what the initial version looked like. Not exactly what I was looking for (skeuomorphic design) but close enough in structure that I can iterate over it.

There is also some bug in it, where clicking on the button doesn't change the state. But overall, this puts us into a good starting point, it created the overall UX layout I expected, stored data in local storage, has the right export feature for Markdown. All of it in just order of minutes instead of hours.
P.S: Sometime I also use v0.dev to bootstrap the UX aspect of the project. That tools allows quicker iteration on the UX aspects.
Small iterations
You don't want to one-shot everything i.e. ask it to do multiple complicated tasks in one go. That can sometime work but can lead to issues and makes it harder (and slower as it will regenerate bunch of code that it doesn't need to change) to iterate. Follow a divide and conquer approach, i.e. split your feature into smaller tasks and iterate over them using the Chat/Composer.
Now first let's fix the bug and also change the UX. In my spec conversation with o1, I ask it to create a spec for UX focused more on skeuomorphic aspects of it. Then I use the Cursor Composer to update the code. I select the o1 model in this case.
Update @App.tsx @MonthColumn.tsx @MonthColumn.css @App.css to improve the UX, also fix the issue where the state isn't being changed when I click the button.
{PASTE THE UX SPEC}
Here is what it looks like now. So it fixed the bug, and also updated the UX to have some more Led like behavior with depth, some shadows etc. It still look horrible but we will further iterate on that.
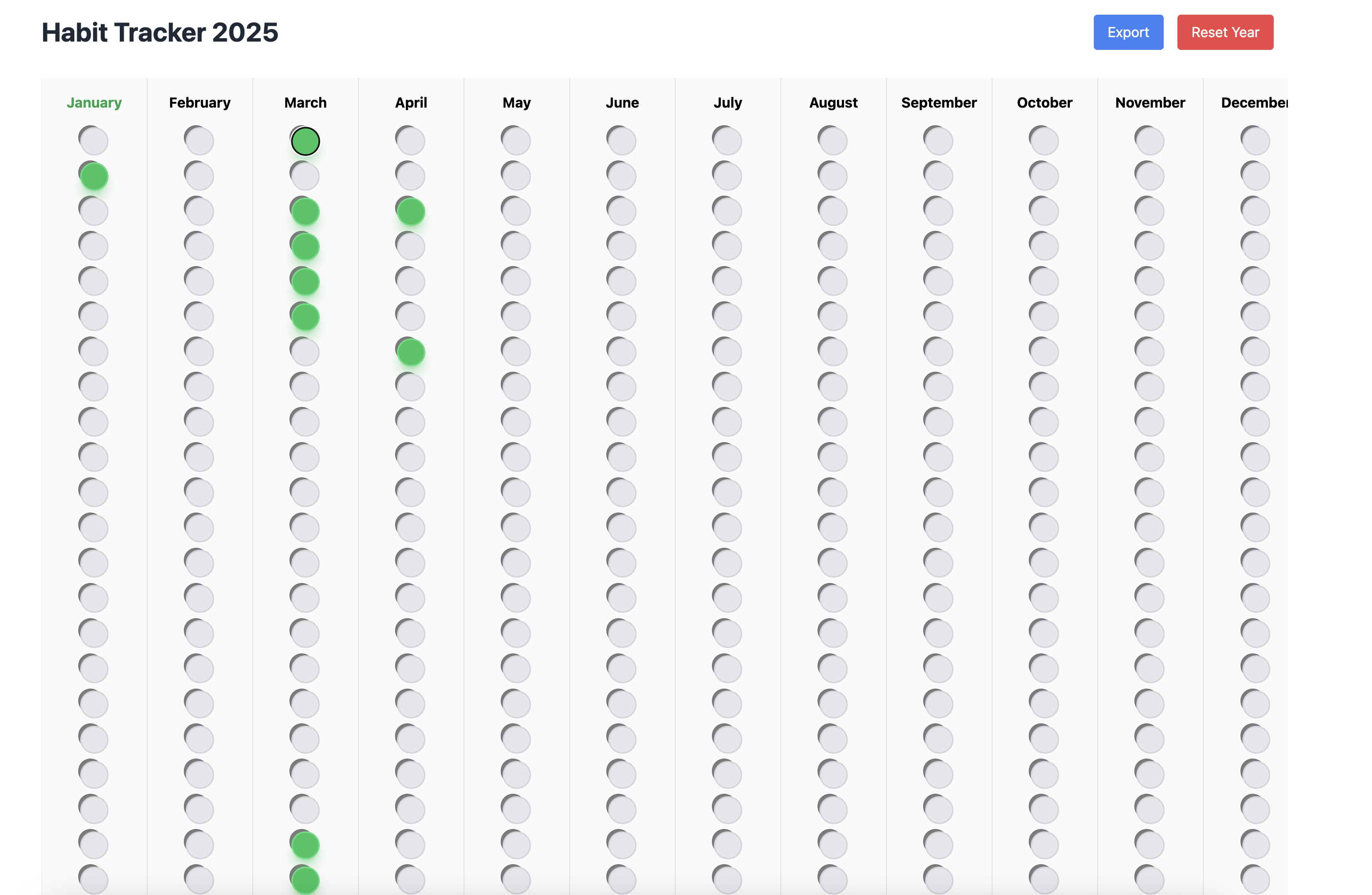
In the next iteration I gave the above screenshot (yes cursor can also use images for context) in Chat mode and first asked it to describe the details the button and then asked it to make necessary changes to replicate that. After couple of more iterations.
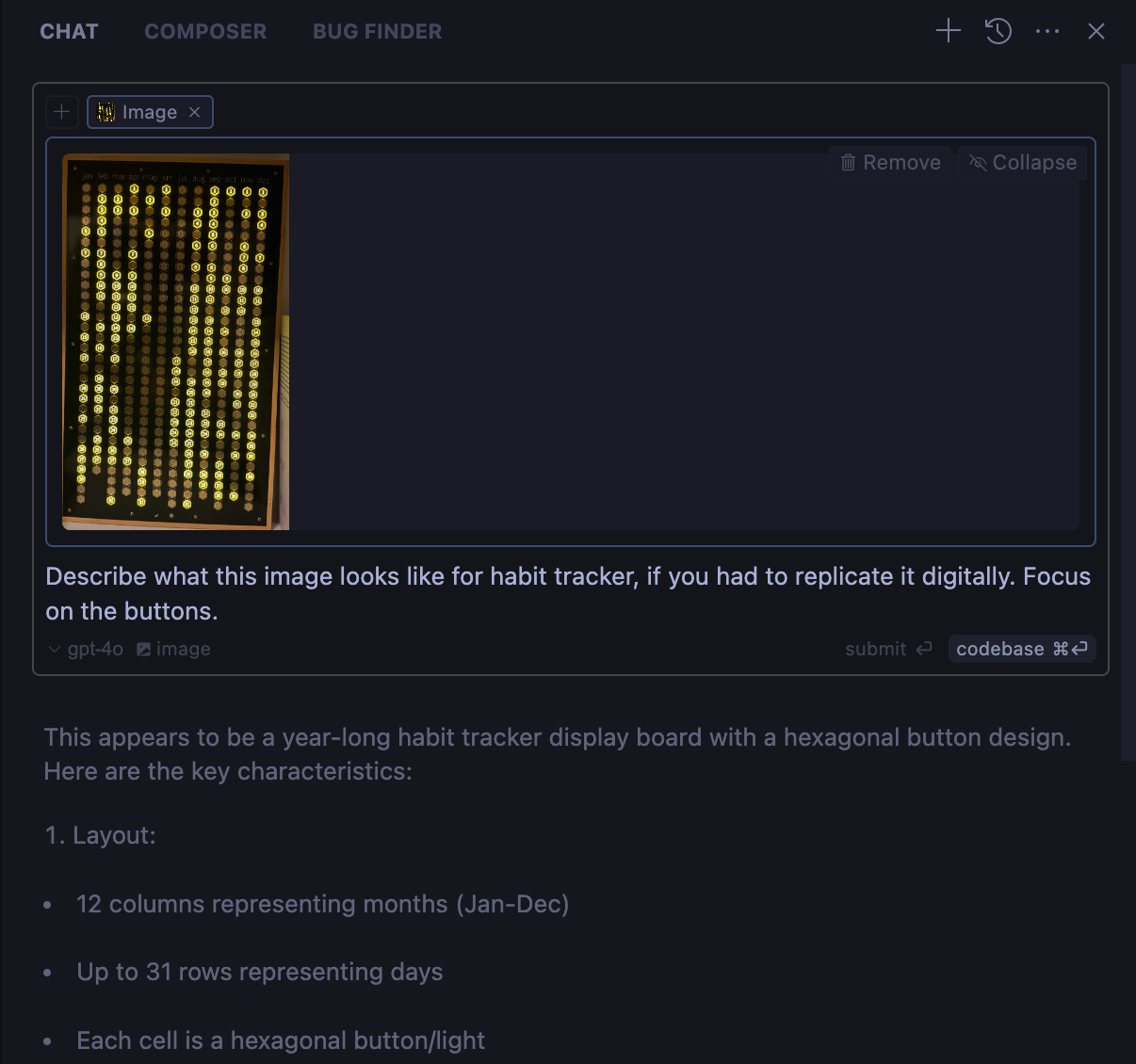
After few back and forth, I have the experience which looks good enough for the demo here.

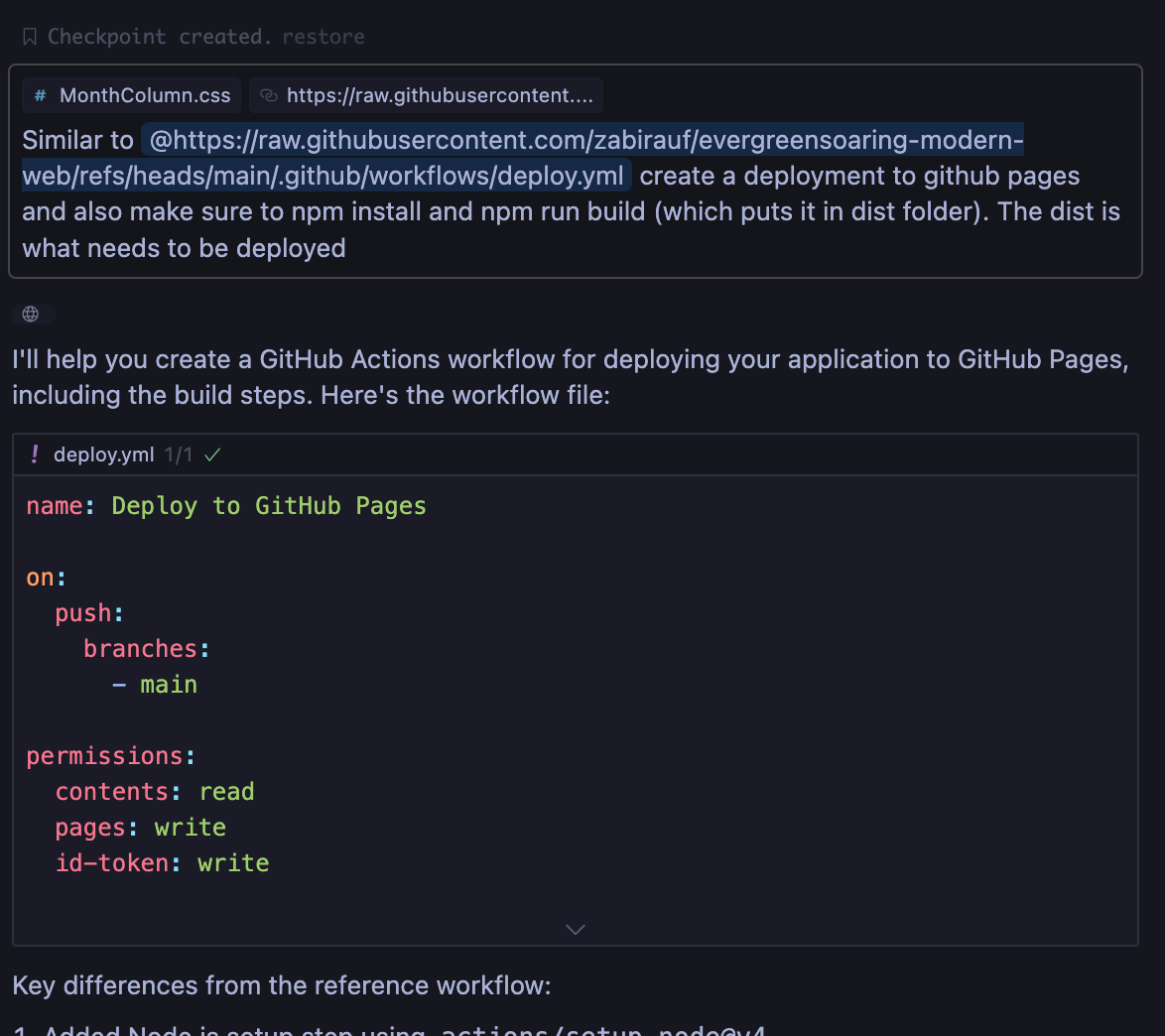
Now finally I need to setup deployment using GitHub actions, so whenever I check-in to main, it builds and deploys to GitHub pages. I already had a workflow in another of my repository that I wanted it to use as context and make specific changes to build this project. The good thing about Cursor is that you can also provide context by adding a link, so either its some existing code, some documentation, it can be passed to LLM for context. In my experience providing relevant context generally allows it to output better code and avoid hallucinations.
Similar to @https://raw.githubusercontent.com/zabirauf/evergreensoaring-modern-web/refs/heads/main/.github/workflows/deploy.yml create a deployment to github pages and also make sure to npm install and npm run build (which puts it in dist folder). The dist is what needs to be deployed
https://zabirauf.github.io/habit-tracker-example/
Overall tips
- Use LLM to hash out the details of the project and store it for further context
- Use a tool or open-source template to bootstrap your project to setup all the necessary toolings and following a manageable project pattern.
- Leverage Cursor Composer (agent mode) to bootstrap the project
- Use mix of o1 and claude-3.5-sonnet. Generally I use o1 where broad stokes are needed e.g. 1st draft of a feature and then use Claude-3.5-Sonnet to further iterate on it. But I'm using Claude-3.5-sonnet approx. 80% of times.
- Select the right mode e.g. Chat, Composer (normal), Composer (agent).
I use Chat, when I need back and forth and know exactly where changes will be and want to see the changes before applying.
I use Composer (normal) when I need multi-file changes e.g. new feature.
I don't use Composer (agent) often enough yet. Composer (agent) can run commands in terminal, lint code, re-iterate etc, but going back to the principle of small iterations, I try to scope things to what I can review easily and add. - Provide relevant context as much as possible e.g. specific files you want changed, specific docs (links), or submit with codebase option in chat when you want it to search for relevant context.
- Store markdown files relevant to your project so you can add those as context e.g. SPEC.md, documentation from website that you often get back from (plugging https://webtomarkdown.com for converting a website documentation to Markdown and storing it 😄)
- Create and use .cursorrules file in your project directory for instructions that you want it to take in prompts, e.g. if you see it always using some library you don't want then add it to .cursorrules, specific technology that you want it to user in code e.g. Tailwind, certain component library e.g. Shadcn etc. This allows you to start nudging it in direction you want for most of your prompts.
- Always make sure that you understand the code at high level so you don't land in a space where eventually it's such a messy code that it becomes hard for you to debug when LLMs can't find issues for you. My tip is to continue to split stuff into manageable pieces (hint, you can use LLMs to do it from time to time).
Closing remarks
I hope this has been helpful, and that you can start finishing the first versions of your projects and deploying them. By turning unfinished projects into completed and deployed ones, you can continue to build momentum even when you take small breaks. This approach allows you to gradually add more to your projects while keeping them manageable. I believe this also helps keep me motivated, as I get to see progress more quickly on what I want to deliver.

{kind=link}